- 首页
- 正文
用scrapy爬取自己博客的文章
用scrapy框架可以非常方便地爬取网站的内容,只需要简单写一些业务处理,同时配置好数据库还有一些参数配置就可以了,下次可以拿这个模板改一下业务来重复使用 我们爬取内容可以使用深度优先和广度优先,默认深度优先,这篇就先用scrapy爬取自己博客作为例子
爬取方法
- 深度优先
从起始页开始,选择一个链接,再选择一个链接不停地跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接
- 广度优先
会爬取起始页中的所有网页,然后在选择其中的一个网页,继续抓取在此网页中链接的所有网页
爬取思路
- 常规化
比如说要爬取一个博客的所有文章,可以根据是否还有分页来不停爬取博客的文章,而每一页又有很多文章,可以把这些文章做个循环爬取,其实所有网站都可以利用这种方法来爬取
- 特殊化
比如说要爬取拉勾网的所有的java职位,这时候就不能用分页的方法了,但可以利用正则来判断是否是java职位的网页,不停地爬取是java职位的网页
这两个种方法我们后面都会给出例子的,这里先用常规化的方法来爬取博客的内容
反爬措施
- 模拟浏览器,设置 header 头部信息
- 模拟人的行为,设置爬取的速度
- 模拟同时多人访问的行为,使用高匿代理IP不停地换ip
- 模拟浏览器,selenium+phantomjs来爬取 ajax 的网站
预备知识(不会详细写,可自行网上查找相关内容)
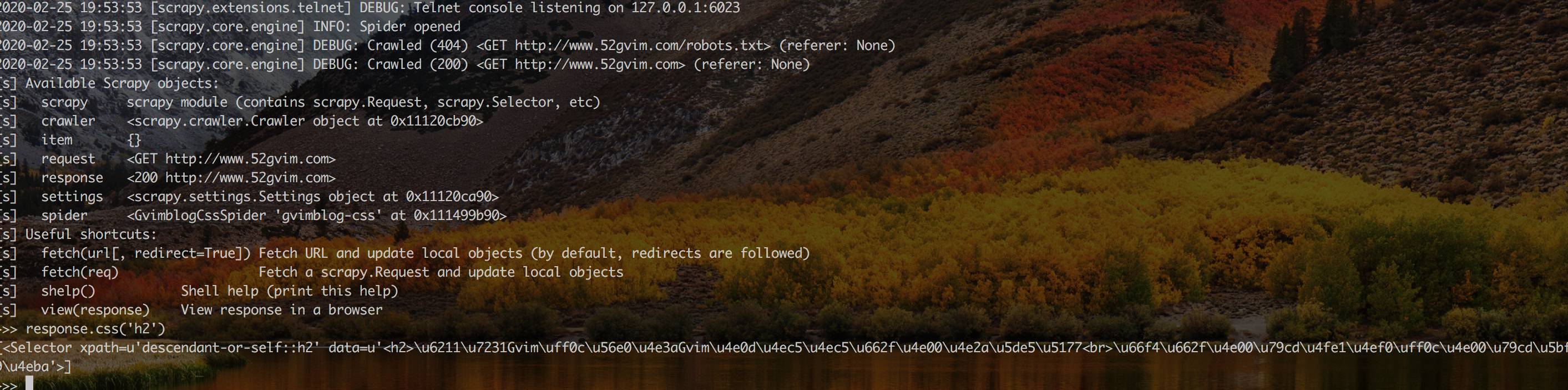
- scrapy shell
scrapy shell是一个交互式shell,您可以在这里调试你的抓取代码,而无需运行爬虫程序,在命令行里使用 scrapy shell
启动scrapy shell
- 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等
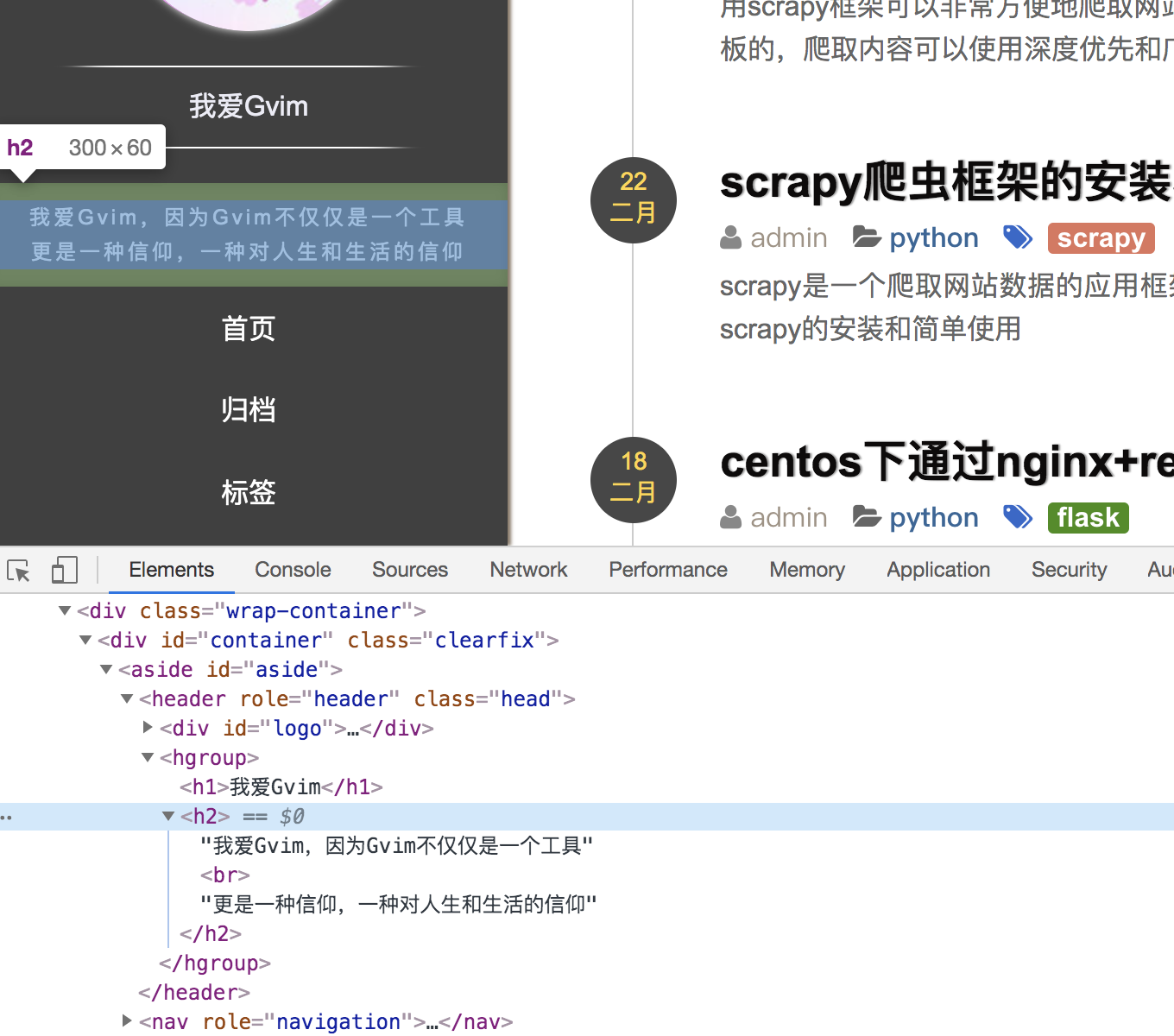
- CSS选择元素
比如我们想获取下图h2的元素,可以在代码或者scrapy shell中使用respose.css('h2')
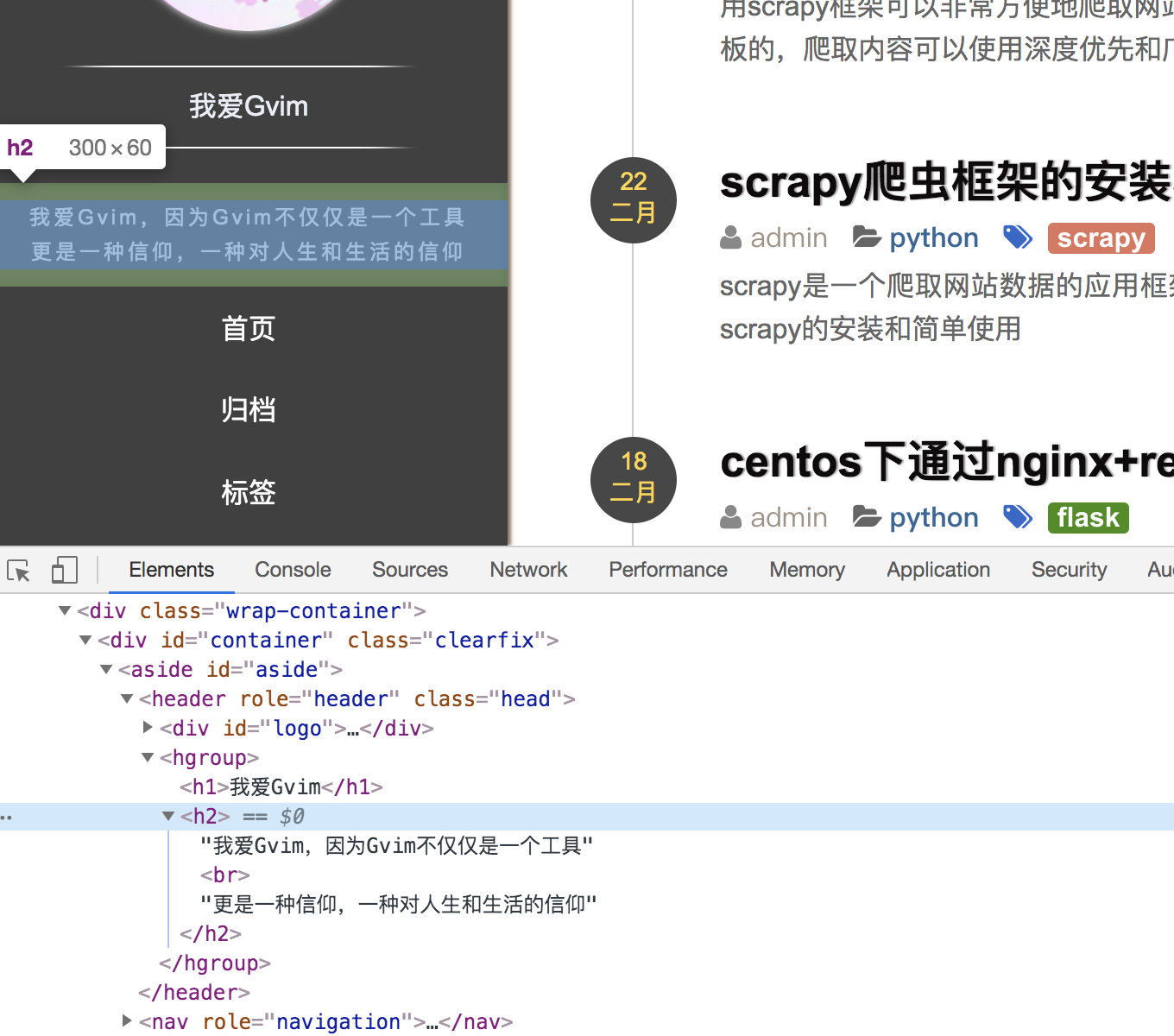
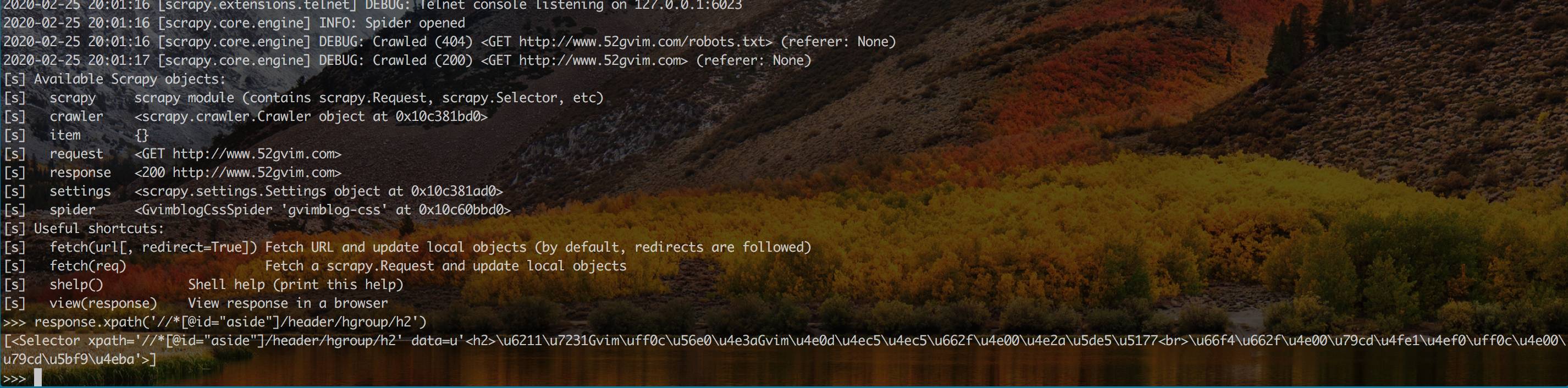
- XPath选择元素
比如我们想获取下图h2的元素,可以在代码或者scrapy shell中使用respose.xpath('//*[@id="aside"]/header/hgroup/h2')
数据库基础
python 基础
创建项目
scrapy startproject scrapyBlog
cd scrapyBlog
scrapy genspider gvimblog-css 52gvim.com
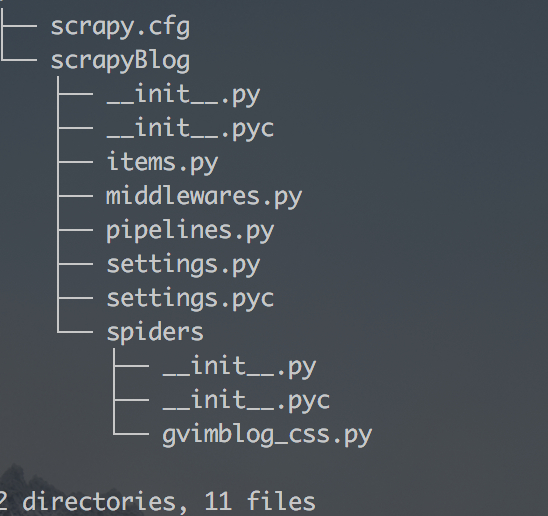
项目结构
修改创建的爬虫类
- 进入到爬虫类的目录
cd scrapyBlog/scrapyBlog/spiders/
- 修改 gvimblog_css.py 的内容如下
# -*- coding: utf-8 -*-
import scrapy
class GvimblogCssSpider(scrapy.Spider):
name = 'gvimblog-css'
allowed_domains = ['52gvim.com']
start_urls = ['http://52gvim.com/']
def parse(self, response):
for item in response.css(".article"):
print '====='
print item.css("h1 > a::text").extract()
print '====='
- 部分变量和方法
name:标识爬虫。它在项目中必须是唯一的,也就是说,您不能为不同的Spider设置相同的名称。
allowed_domains:允许哪些域名能够爬取
start_urls:从网站的那个地址开始爬取,可以设置多个
parse():将被调用来处理为每个请求下载的响应的方法。 response参数是一个TextResponse保存页面内容的实例,并且具有更多有用的方法来处理它。
- parse 方法
for item in response.css(".article"):
print '====='
print item.css("h1 > a::text").extract()
print '====='
上面这些代码就是我们要处理的爬虫业务,当然,这里只是最简单的抓取了第一页的所有文章的标题,处理的逻辑是这样的:先用 css 方法获取所有的标题的元素,然后把这些元素做一个循环调用
完整例子
- 修改 scrapyBlog/scrapyBlog/spiders/gvimblog_css.py 文件的内容如下
# -*- coding: utf-8 -*-
import scrapy
import urlparse
from scrapy.http import Request
class GvimblogCssSpider(scrapy.Spider):
name = 'gvimblog-css'
allowed_domains = ['52gvim.com']
start_urls = ['http://52gvim.com/']
def parse(self, response):
# 把当前页的所有文章做一个循环
for item in response.css(".article"):
post_url = item.css("h1 > a::attr(href)").extract_first('')
# 把当前页的每一篇文章的地址传给 parse_detail 方法,在parse_detail获取特定内容
yield Request(url=urlparse.urljoin(response.url, post_url),
callback=self.parse_detail)
# 获取下一页的地址,不停地爬取下一页的内容
next_url = response.css(".page > a.next::attr(href)").extract_first('')
if next_url is not None:
yield Request(url=urlparse.urljoin(response.url, next_url),
callback=self.parse)
def parse_detail(self, response):
# 拿到每一篇文章里面的内容,然后交给 pipelines.py 处理
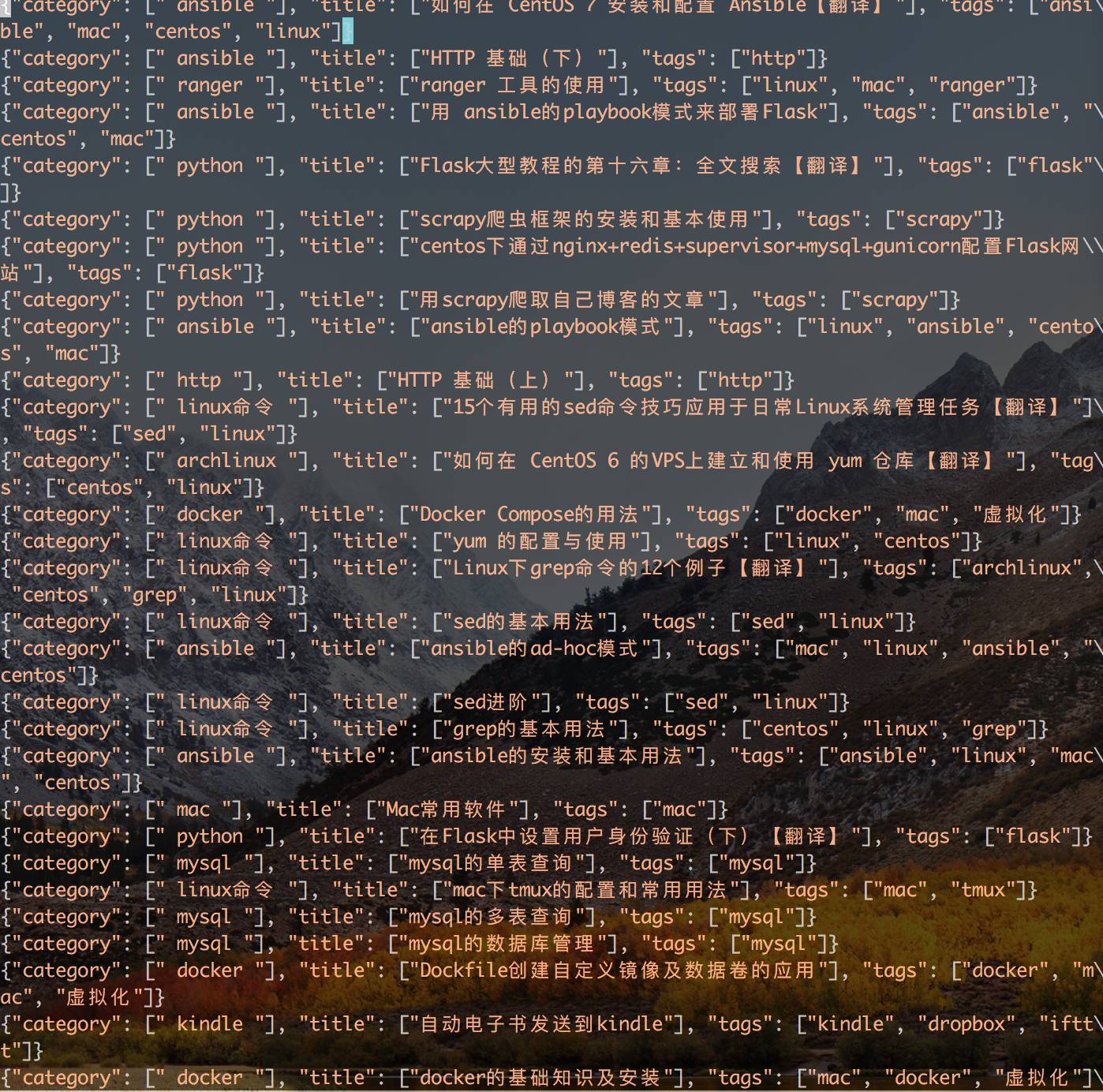
yield {
'title': response.css('.article h1::text').extract(),
'category': response.css('.article .icon-category a::text').extract(),
'tags': response.css('.article .icon-tags a::text').extract()
}
- 修改 scrapyBlog/scrapyBlog/pipelines.py 文件的内容如下
# -*- coding: utf-8 -*-
import json
import codecs
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class JsonWithEncodingPipeline(object):
def __init__(self):
self.file = codecs.open('blog.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def close_spider(self, spider):
self.file.close()
- 修改 scrapyBlog/scrapyBlog/settings.py 文件,把ITEM_PIPELINES的注释去掉,并改为下面的内容
ITEM_PIPELINES = {
'scrapyBlog.pipelines.JsonWithEncodingPipeline': 300,
}
- 运行爬虫
scrapy crawl gvimblog-css
- 运行结果,可以看到在根目录生成了一个 blog.json 文件,内容如下