- 首页
- 正文
部署scrapy爬虫
我们在上一篇文章中已经实现了一个获取向下滚动展示更多数据的内容,这一篇文章里我们要把这个爬虫部署到免费的云服务器( https://www.zyte.com ),这个云服务器可以使用 python2 或者 python3,这里我们使用 python3 来部署
预备工作
- python3.7.4
- scrapy 2.7.0
- virtualenv 15.2.0(python3的使用
python3 -m venv venv来创建虚拟环境)
注册账号并创建新项目
- 到 https://www.zyte.com 去注册一个账号
- 登录账号进到后台首页,会看到一个
Create Project的按钮,点击这个按钮,在弹出框里输入项目的名字,我们这里输入scrapy-scroll
上传本地的项目文件
- 点击
Code & Deploys,就可以看到下面的界面:
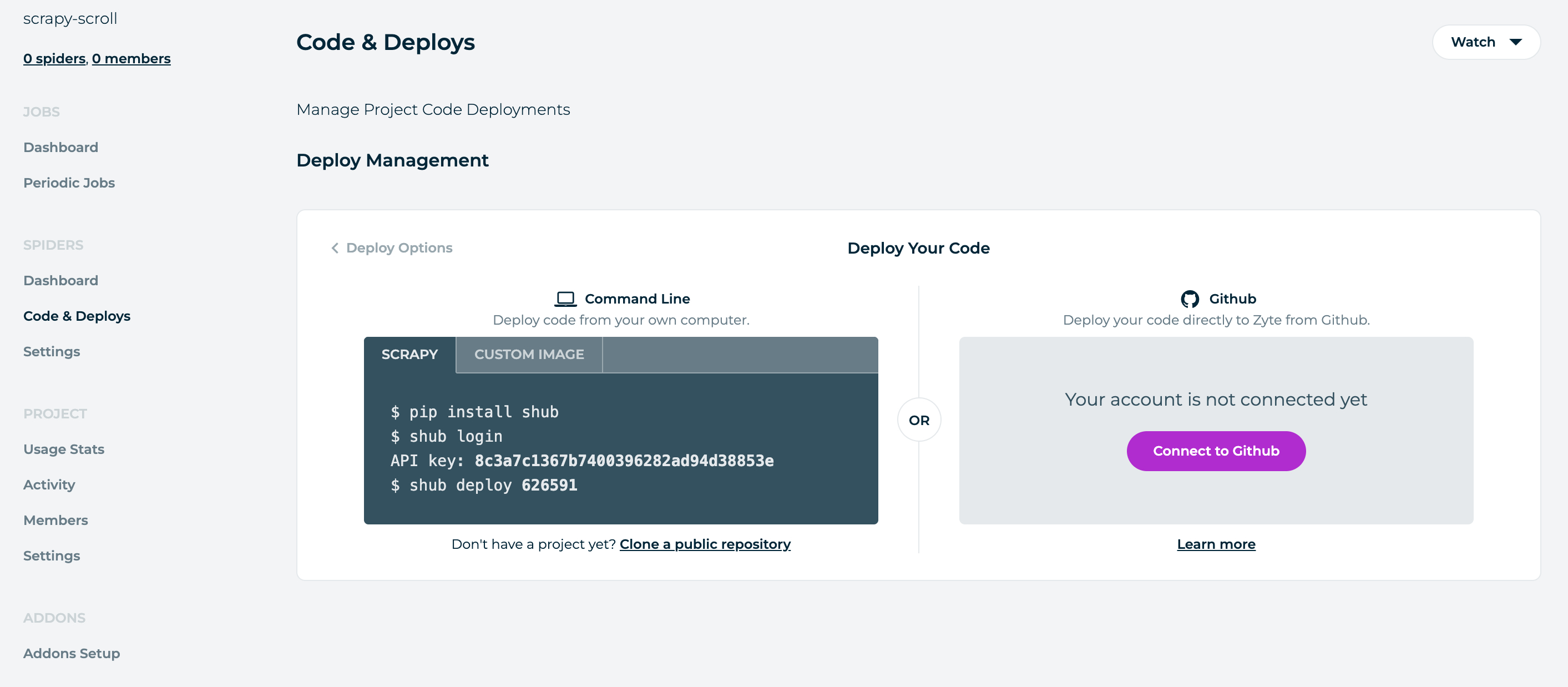
- 进到我们本地的项目
scrollquotes,在命令行下执行下面的操作:
$ cd scrollquotes
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install shub
$ shub login # 输入上面图片的 API key
$ shub deploy 626591
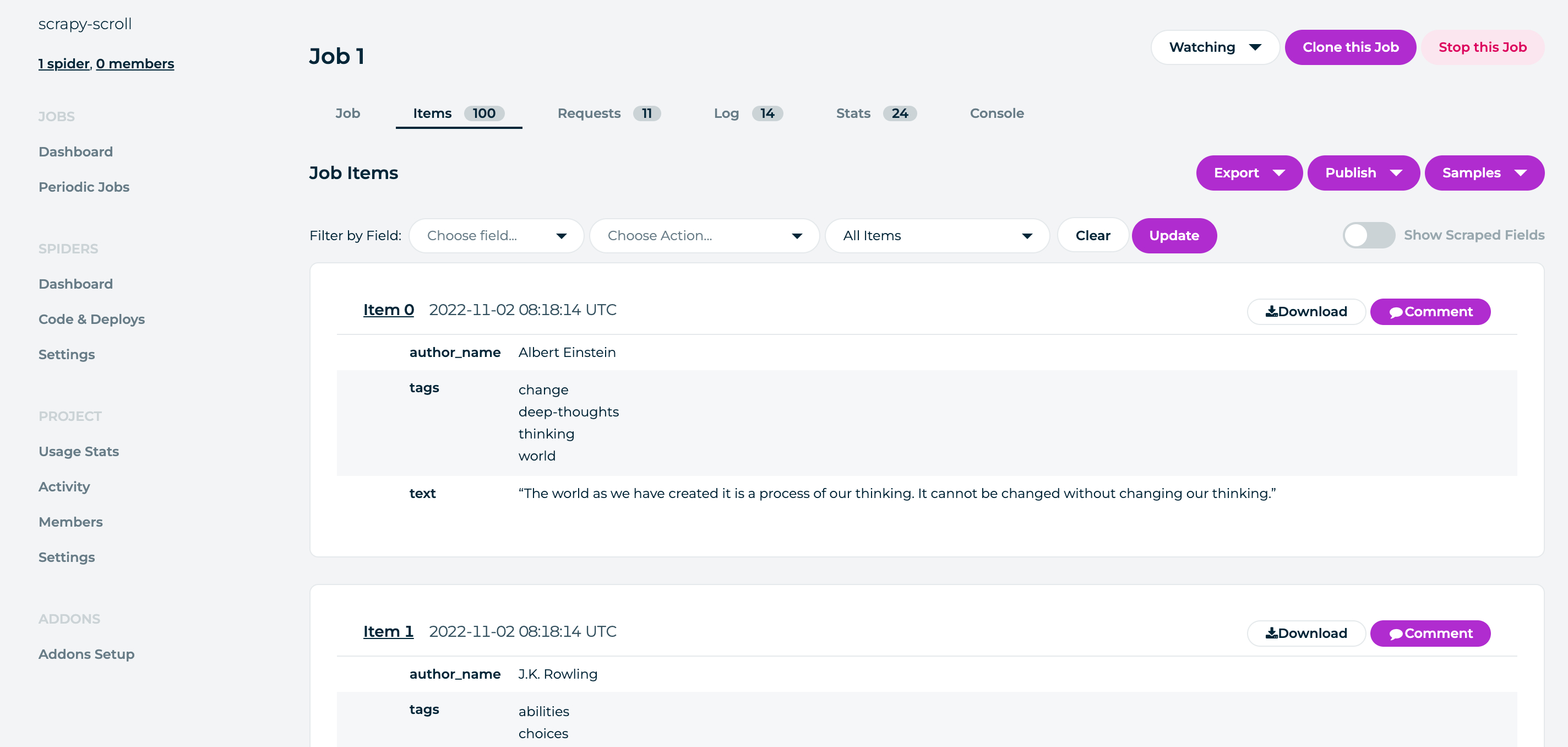
执行完上面的命令,就会把我们本地的项目上传到线上,点击
Dashboard,再点击Run按钮就可以执行我们的爬虫了。下面是我获取到的数据:
我们可以发现这个云服务器是有提供定时爬取的功能,但是是收费的,有没有其它的方式实现定时爬取数据呢?答案是有的,我们可以使用 SpiderKeeper
,SpiderKeeper 是一款开源的spider管理工具,在本地部署或者买个 vps 来进行部署都可以的,下面我们在本地项目上进行操作:
安装相关的包
$ cd scrollquotes
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install scrapy
$ pip install scrapyd
$ pip install scrapyd-client
$ pip install spiderkeeper
scrapyd是一个用来部署和运行scrapy爬虫的应用。它可以让你部署(上传)你的项目和通过 JSON API 来控制它们的爬虫。scrapyd-client可以把本地的项目打包给 scrapyd 来用的。如果在安装包的时候出现这个错误:Could not install packages due to an EnvironmentError: Missing dependencies for SOCKS support,可以输入下面的命令,然后再安装就可以了
unset all_proxy && unset ALL_PROXY
启动 Scrapyd
$ cd scrollquotes
$ scrapyd
打开 http://127.0.0.1:6800/,可以看到 scrapyd 服务已经在运行了
启动 SpiderKeeper
$ cd scrollquotes
$ spiderkeeper
- 打开
http://127.0.0.1:5000/,可以看到 spiderkeeper 服务已经在运行了,这里输入用户名(admin)和密码(admin)就可以进到后台了,其实spiderkeeper是一个 flask 写的程序,可以在 虚拟环境中找到这个包来修改配置信息
- spiderkeeper 的后台界面
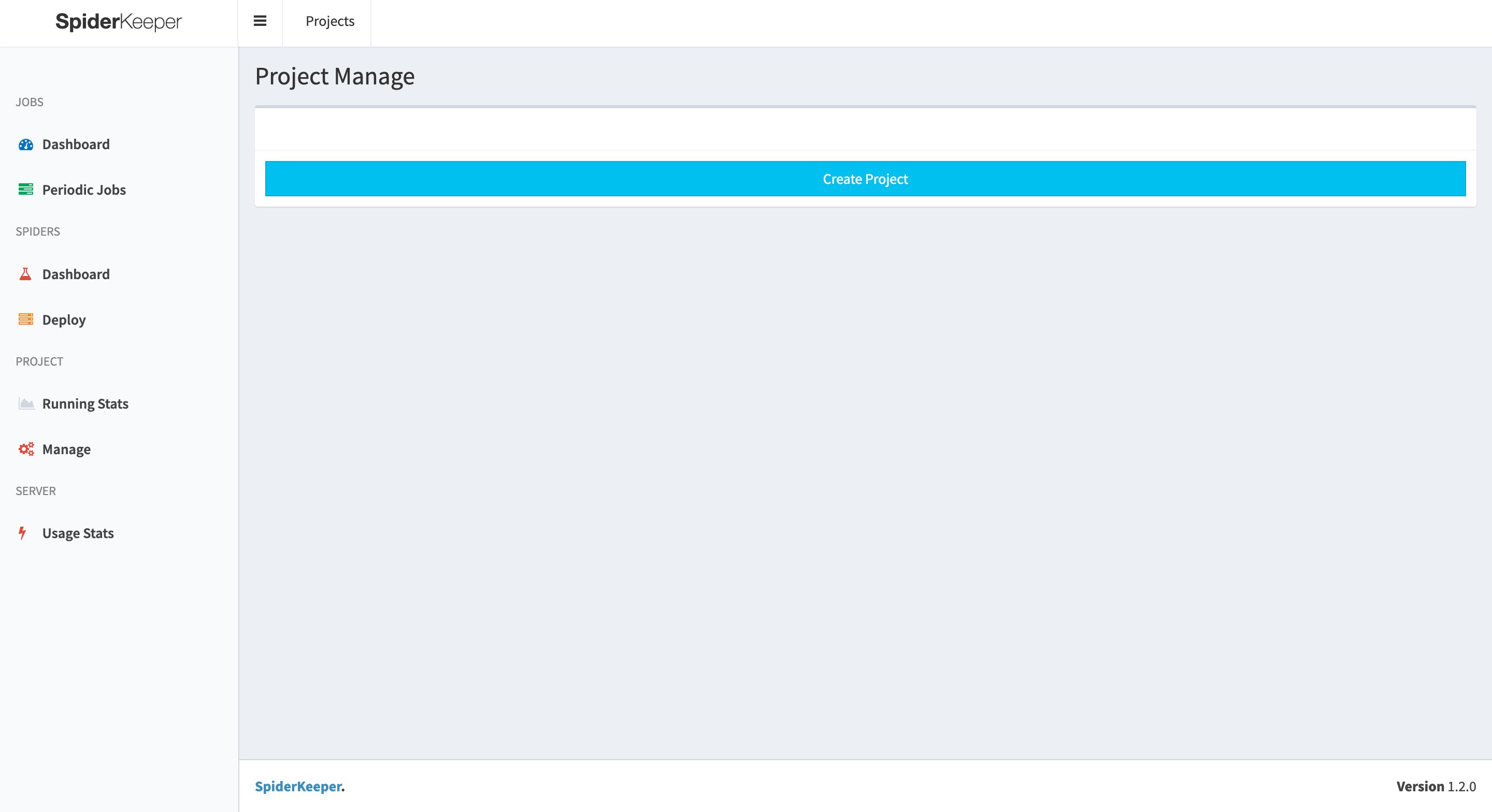
点击 Create Project 创建一个名为 scrapy-scroll 的项目
打包 egg 文件
$ cd scrollquotes
$ scrapyd-deploy --build-egg output.egg
把 egg 文件上传到这里:
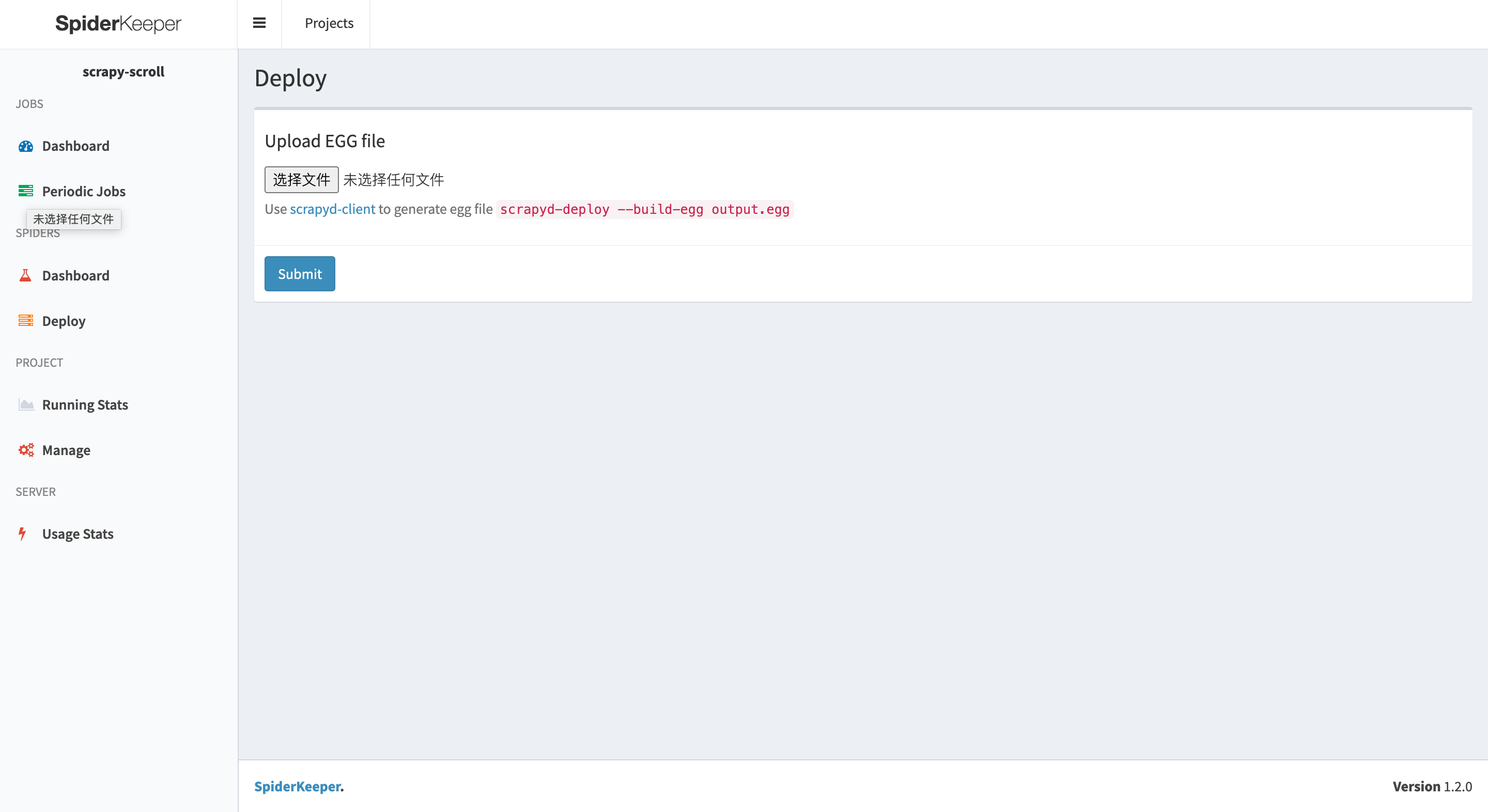
运行爬虫
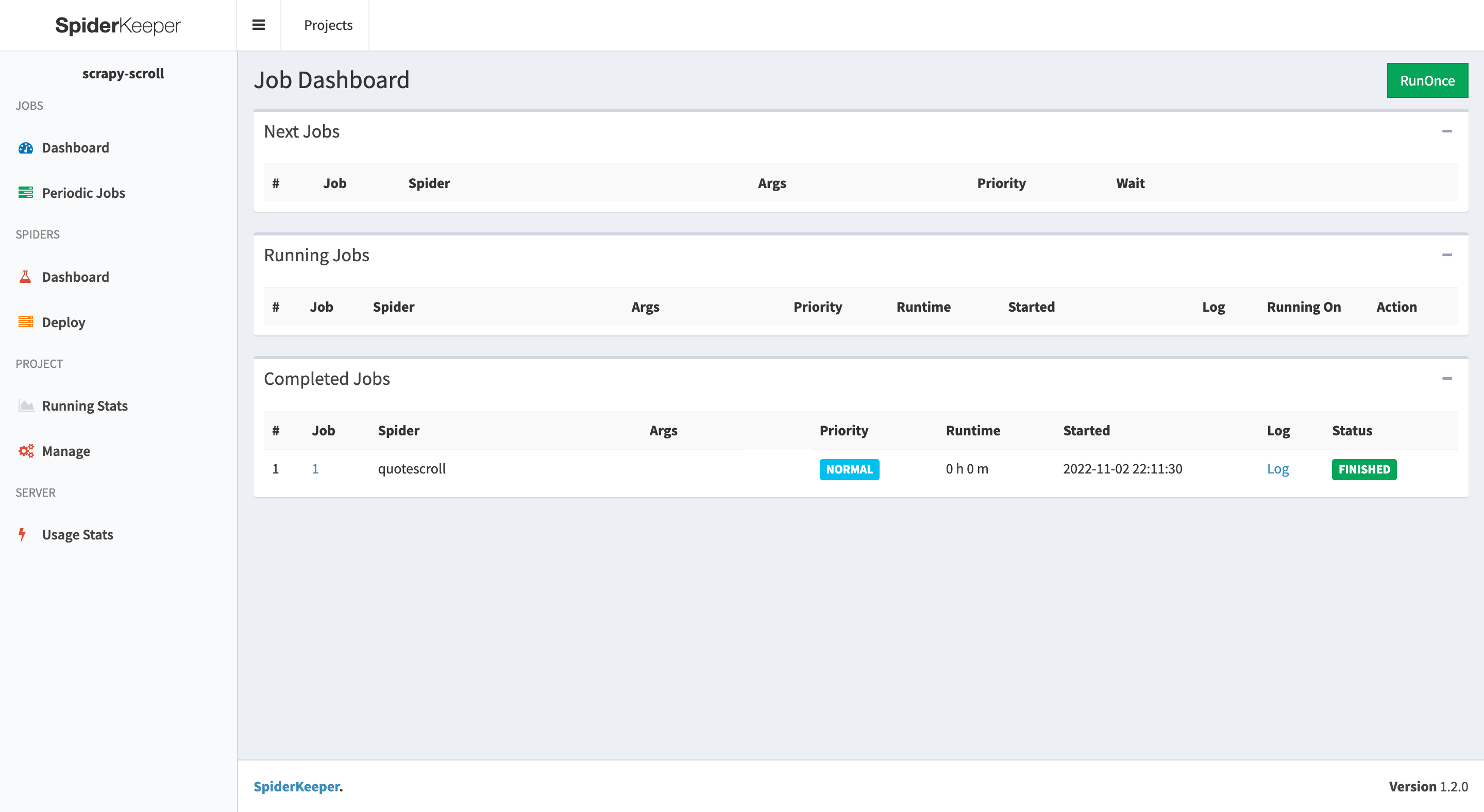
点击 Dashboard,然后再点击 RunOnce 按钮,就会看到爬虫在运行了,但只会运行一次
定时执行爬虫任务
点击 Periodic Jobs,再点击 Add Job,选择每一分钟执行一次,如下图所示:
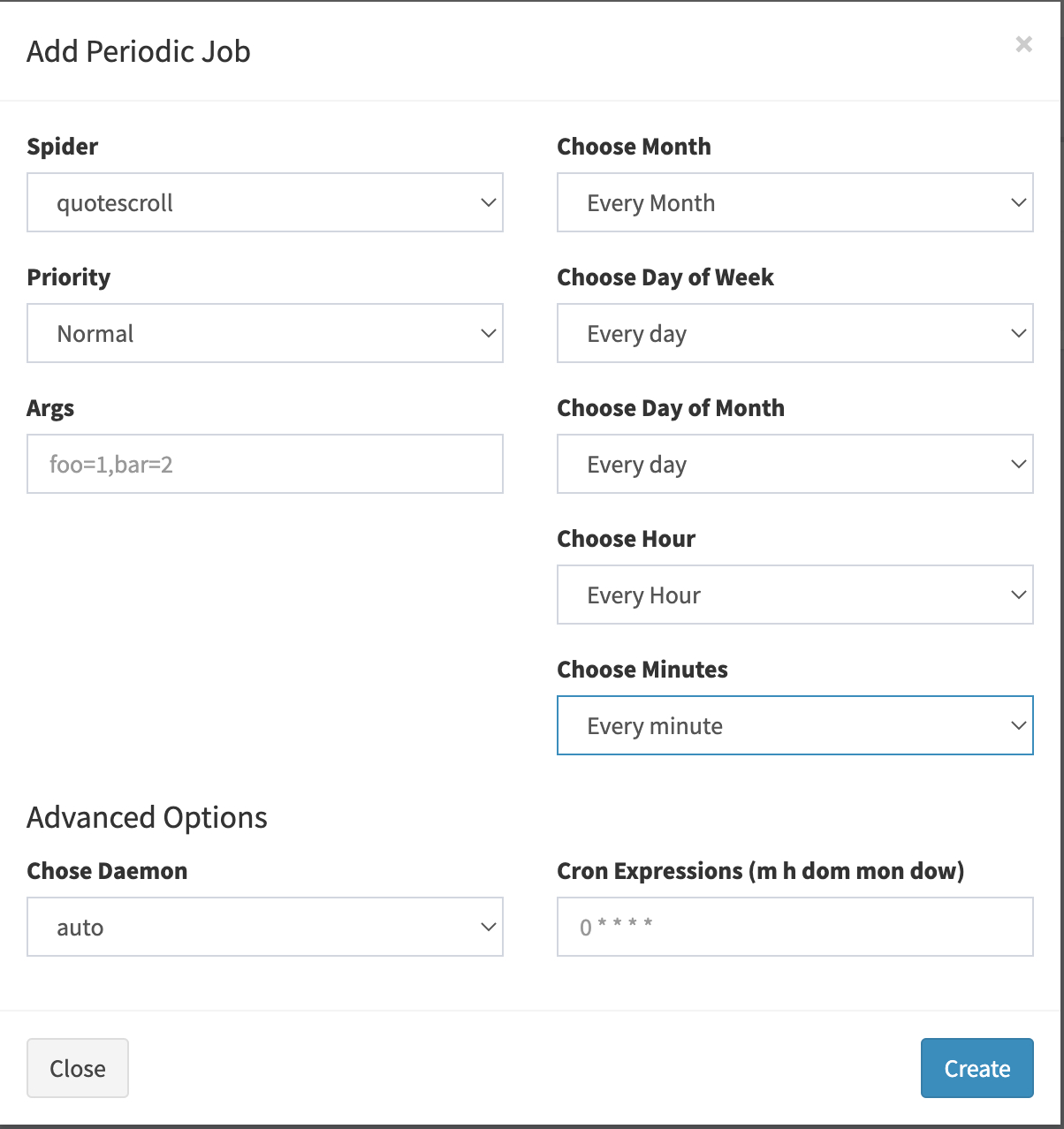
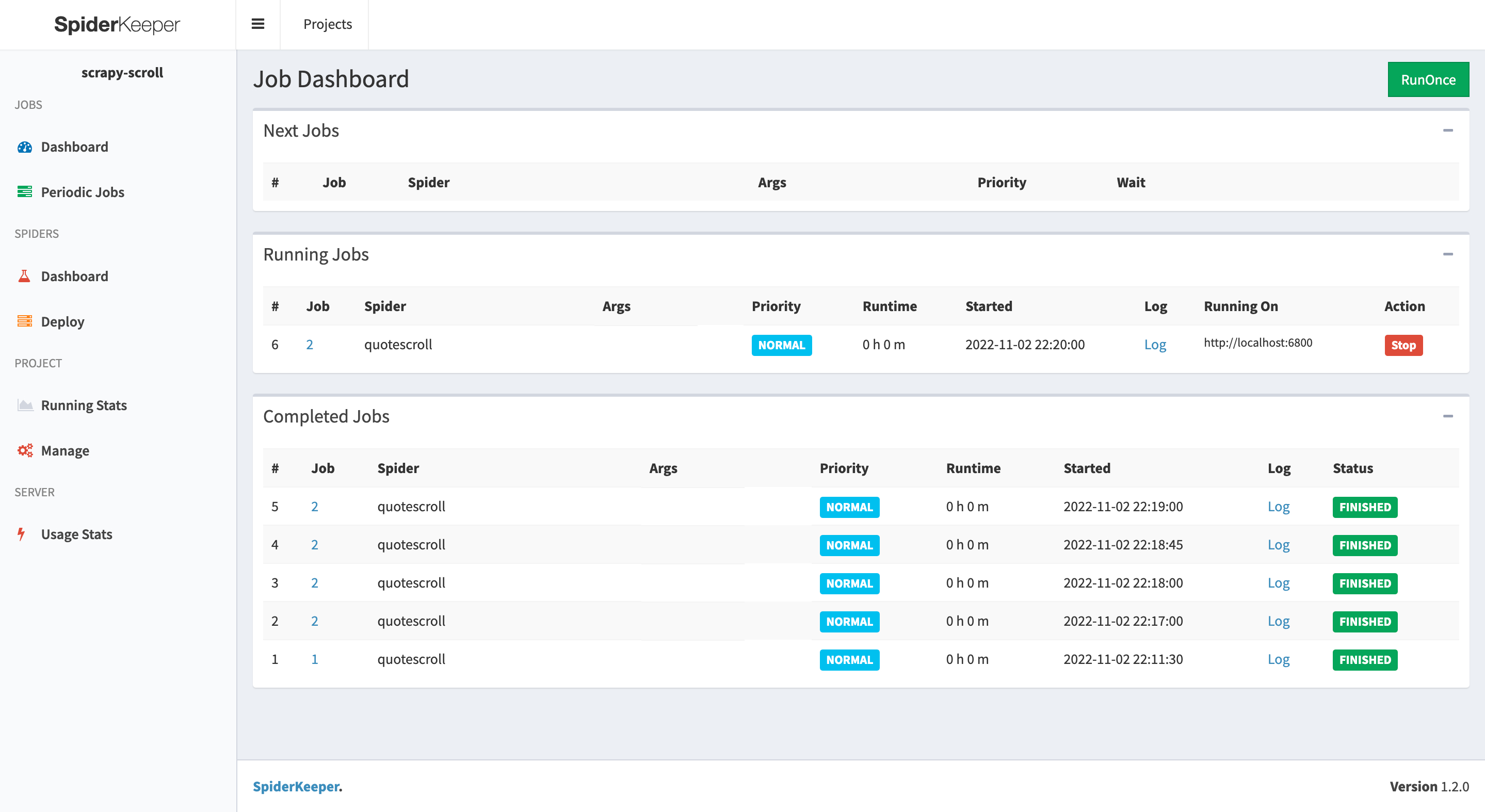
再点击列表里的 Run,就可以执行这个任务了
参考链接
【上一篇】用scrapy爬取向下滚动更多内容的网站